
Upload pre-annotations
Updated at September 6th, 2023
Step 1: Format your annotation data
Let's get started. First, you need to ensure that your annotation data format is compatible with Sama's format.
- Format your data using the Sama JSON structure
Step 2: Use the API
All you need to do is to call the “Create task” endpoint. If you want to take a closer look at the endpoints and how they work, you can go here and check the documentation.
Here is an example of a python script that shows how you can call the API.
url = f"https://api.sama.com/v2/projects/{project_id}/batches.json?access_key={client_access_key}"
sama_data = [
{
"data": {}
}
]
payload = {"tasks": sama_data}
headers = {
"Accept": "application/json",
"Content-Type": "application/json"
}
# POST request
response = requests.request("POST", url, json=payload, headers=headers)
print(response.text)
Examples of model predictions
- Rectangle image model predictions
- Polygon image model predictions
- Point image model predictions
- Key-points image model predictions
- Cuboid 3D image model predictions
- Slide-rectangle image model predictions
JSON format for model predictions
Don’t feel overwhelmed by the JSON format. We are going to walk you through the different sections inside the JSON
-
The data : This section lists the inputs as they are defined in the project settings. If you don’t know how to see your inputs, go [here](https://sama.readme.io/v2.0/docs/preparing-jsons-to-upload-tasks#viewing-the-task-input-schema) and follow the tutorial.
If you already know your inputs, you can start getting the corresponding data, follow [this tutorial](https://sama.readme.io/v2.0/docs/preparing-jsons-to-upload-tasks#preparing-a-json-with-your-tasks) if you are not sure about the process.
- The output : This section consists of a dictionary of the outputs defined in the project settings, but in the JSON this name comes with the prefix output\_ (e.g “output_YOUR_OUTPUT_NAME”).
Inside this section, you can have some other nested inputs depending on the annotation type you are working with.
Some nested inputs you can find inside the JSON
| JSON key | Dscription | Present in |
| layers | Corresponds to all the annotations on a task. There are two types "vector_tagging" and "raster_coding" | Vector and Raster |
| vector taging | Layer type that corresponds to vector annotations. Graphics are composed of paths | Vector |
| raster coding | Layer type that corresponds to raster annotations. Graphics are composed of pixels | Raster |
| shapes | List of all shape annotations performed on the task. One task can have more than one shape. For example, it can have a rectangle and a polygon | Vector |
| mask url | Corresponds to an asset that contains the mask of an annotation. This is stored as a URL in an S3 bucket | Raster |
| tags | Key value pair that enables the annotation | Vector, Raster, Video and 3D Point Cloud |
| type | Corresponds to the vector tool type (e.g., rectangle, polygon, arrow, cuboid) | Vector, Video 3D Point Cloud |
| points | An array of (x,y) pairs for every point in the annotation. (e.g., \[[x, y], [...]]) | Vector, Video,3D Point Cloud |
| key location | Describes what a specific shape looks like on the keyframes annotated by the associate | Video |
| frame number | Refers to its index in the list of all frames. | Video |
| frame count | Total number of frames in a video | Video |
| visibility | Denotes whether the shape is visible or not in that frame. | 3D Point Cloud |
| location | Describes what a specific shape looks like for every single frame of the video. Between keyframes, linear interpolation is automatically applied. | 3D Point Cloud |
Examples
Rectangle
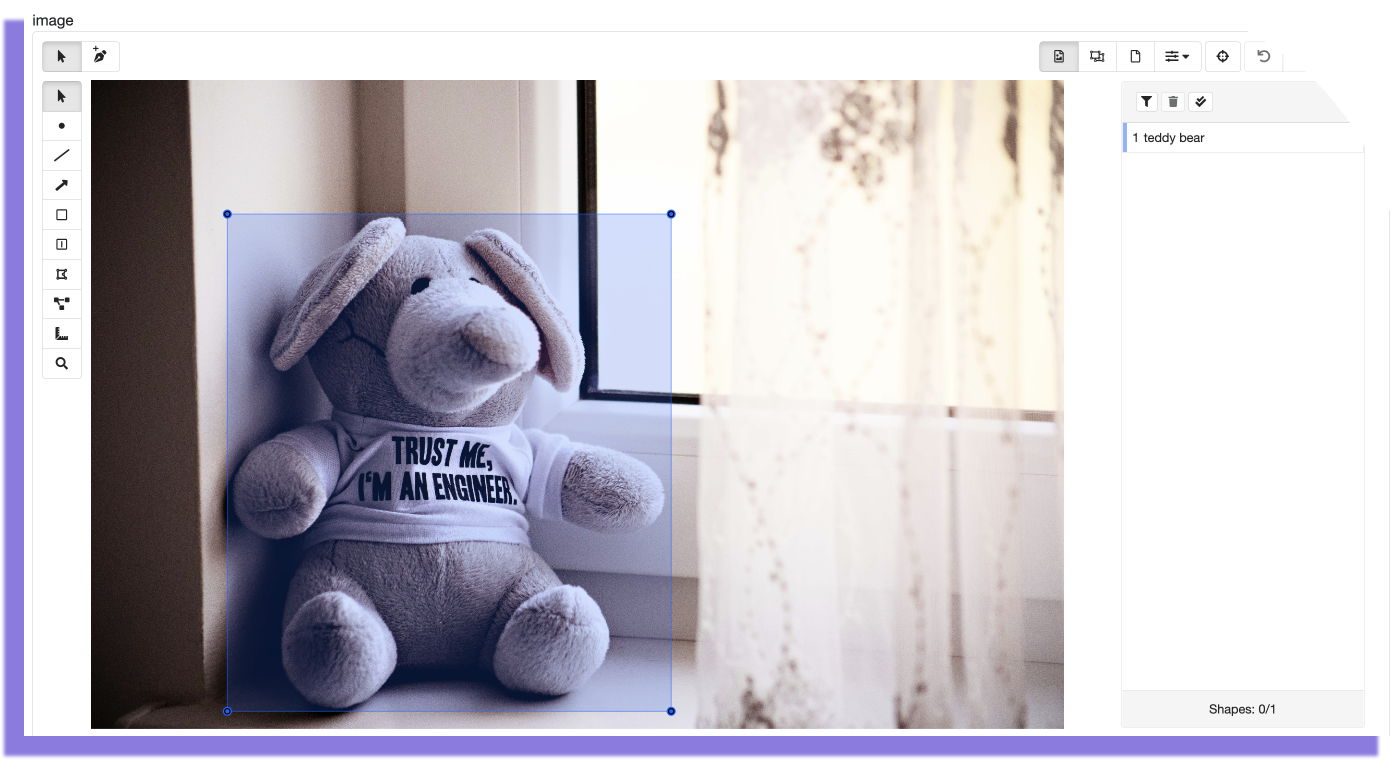
This annotation corresponds to the following output:
Rectangle JSON output
[
{
"data":{
"url":"https://sama-client-assets.s3.amazonaws.com/doc-tutorial/Image%20Annotation/teddy-bear.jpg",
"name":"Teddy Bear",
"output_image":{
"layers":{
"vector_tagging":[
{
"shapes":[
{
"tags":{
"category":"teddy bear"
},
"type":"rectangle",
"index":1,
"points":[
[
840,
826
],
[
3576,
826
],
[
840,
3891
],
[
3576,
3891
]
]
}
],
"group_type":null
}
]
}
},
"output_timeofday":"daytime"
}
}
]
Are you struggling while formatting your shape points?
It is normal to have different representations of coordinates. The Sama Platform draws the shapes using ordered pairs (x, y) for each vertex.
Some formats represent the shapes by a list like [x, y, weight, height], if this is the case, use the following script to get [[x1, y1], [x1, y2], [x2, y1], [x2,y2]] which is how Sama Platform draws a rectangle.
def _from_bbox_to_rectangle(bbox):
x1 = int(bbox[0])
y1 = int(bbox[1])
width = int(bbox[2])
height = int(bbox[3])
y2 = y1 + height
x2 = x1 + width
return [[x1,y1], [x1, y2], [x2, y1], [x2,y2]]Polygon
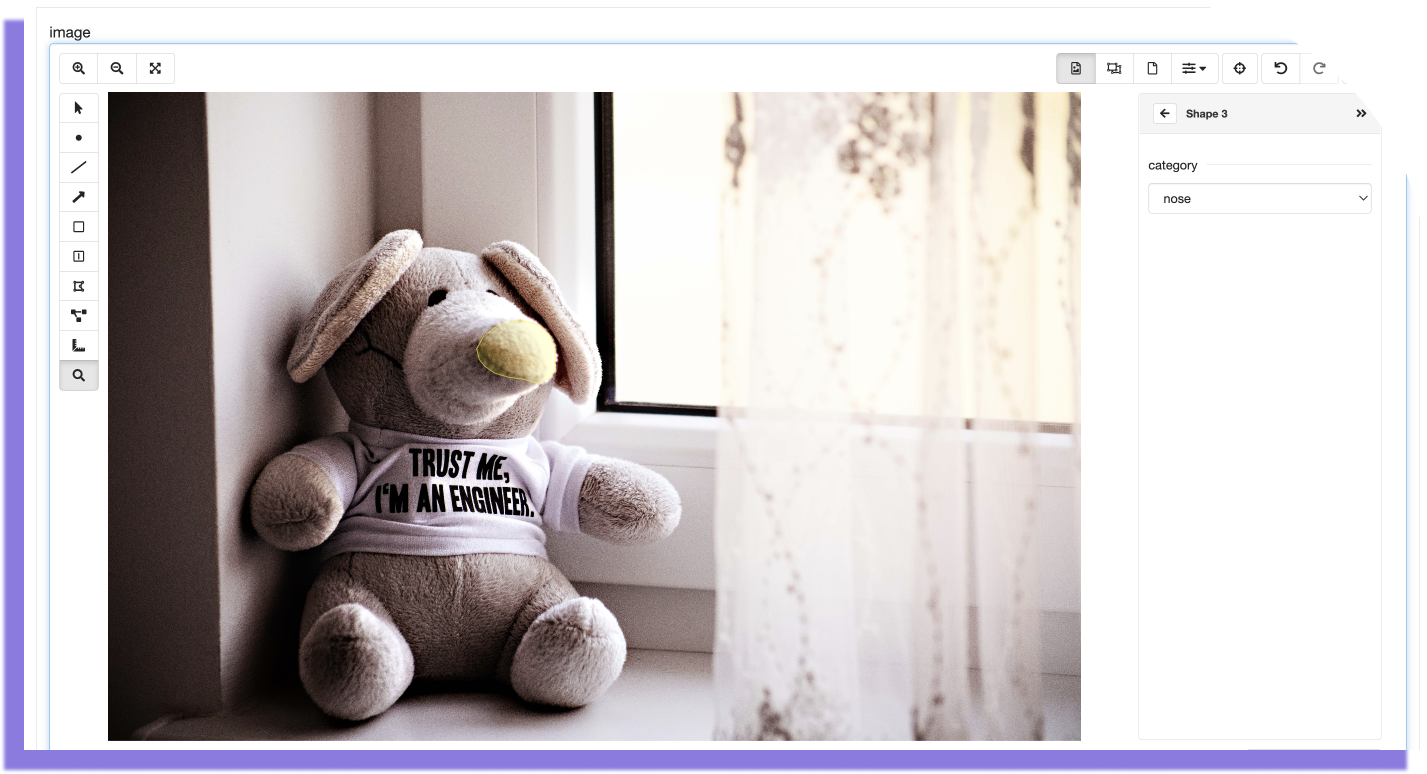
This annotation corresponds to the following output:
Polygon JSON output
[
{
"data": {
"url": "https://sama-client-assets.s3.amazonaws.com/doc-tutorial/Image%20Annotation/teddy-bear.jpg",
"name": "Teddy Bear",
"output_image": {
"layers": {
"vector_tagging": [
{
"shapes": [
{
"tags": {
"category": "nose"
},
"type": "polygon",
"index": 1,
"points": [
[2338, 1487],
[2401, 1437],
[2543, 1403],
[2643, 1432],
[2684, 1462],
[2726, 1503],
[2751, 1566],
[2755, 1628],
[2759, 1707],
[2734, 1753],
[2693, 1774],
[2651, 1795],
[2555, 1770],
[2468, 1758],
[2384, 1733],
[2322, 1691],
[2288, 1649],
[2272, 1582],
[2313, 1507],
[2318, 1503],
[2313, 1503],
[2326, 1503]
]
}
],
"group_type": null
}
]
}
},
"output_timeofday": "daytime"
}
}
]
Point

This annotation corresponds to the following output:
Point JSON output
[
{
"data":{
"url":"https://sama-client-assets.s3.amazonaws.com/doc-tutorial/Image%20Annotation/teddy-bear.jpg",
"name":"Teddy Bear",
"output_image":{
"layers":{
"vector_tagging":[
{
"shapes":[
{
"tags":{
"category":"eye"
},
"type":"point",
"index":1,
"points":[
[
2042,
1266
]
]
}
],
"group_type":null
}
]
}
},
"output_timeofday":"daytime"
}
}
]
Key points

This annotation corresponds to the following output:
Key points JSON output
[
{
"data":{
"url":"https://sama-client-assets.s3.amazonaws.com/doc-tutorial/Image%20Annotation/teddy-bear.jpg",
"name":"Teddy Bear",
"output_image":{
"layers":{
"vector_tagging":[
{
"shapes":[
{
"tags":{
"category":"teddy bear",
"keypoint_class":"skeleton"
},
"type":"keypoint_shape",
"index":12,
"points":[
[
2129,
984
],
[
2104,
2172
],
[
1282,
2463
],
[
3222,
2501
],
[
2173,
3139
],
[
1592,
3524
],
[
2913,
3512
]
]
}
],
"group_type":null
}
]
}
},
"output_timeofday":"daytime"
}
}
]
Cuboid

This annotation corresponds to the following output:
Cuboid JSON output
[
{
"data":{
"url":"https://sama-client-assets.s3.amazonaws.com/doc-tutorial/Image%20Annotation/teddy-bear.jpg",
"name":"Teddy Bear",
"output_image":{
"layers":{
"vector_tagging":[
{
"shapes":[
{
"tags":{
"category":"teddy bear"
},
"type":"cuboid",
"index":8,
"points":[
[
1067,
3948
],
[
1067,
839
],
[
3614,
3941
],
[
3614.0,
839.0135352884305
],
[
840,
3411
],
[
840.0,
840.0383499838865
],
[
2947.46664935038,
3406.211302825499
],
[
2947.46664935038,
840.0476094692384
]
],
"key_points":[
[
973,
845
],
[
3614,
3941
],
[
1067,
3948
],
[
840,
3411
],
[
1067,
839
]
]
}
],
"group_type":null
}
]
}
},
"output_timeofday":"daytime"
}
}
]
Slide Rectangle
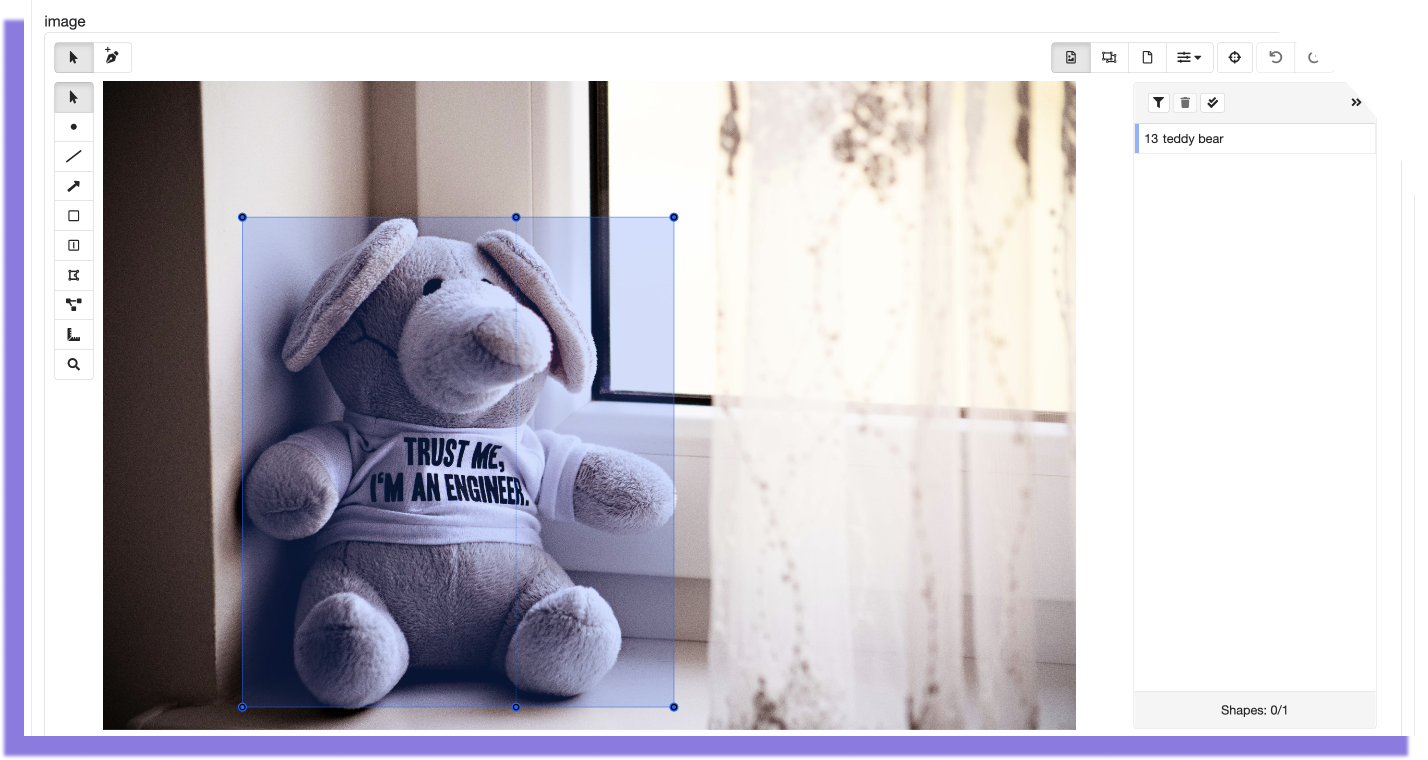
This annotation corresponds to the following output
Slide rectangle JSON output
[
{
"data":{
"url":"https://sama-client-assets.s3.amazonaws.com/doc-tutorial/Image%20Annotation/teddy-bear.jpg",
"name":"Teddy Bear",
"output_image":{
"layers":{
"vector_tagging":[
{
"shapes":[
{
"tags":{
"category":"teddy bear",
"keypoint_class":"skeleton"
},
"type":"keypoint_shape",
"index":12,
"points":[
[
2129,
984
],
[
2104,
2172
],
[
1282,
2463
],
[
3222,
2501
],
[
2173,
3139
],
[
1592,
3524
],
[
2913,
3512
]
]
}
],
"group_type":null
}
]
}
},
"output_timeofday":"daytime"
}
}
]
Video
Importing video pre-annotations
This is an example of how a pre-annotation looks for video annotation. You need to update the “data” inside your JSON:

This annotation corresponds to the following output
Video JSON output
[
{
"data": {
"video": "https://assets.samasource.com/api/v1/assets/ccf5e85e-35e5-470e-9b43-ae5c14271823?linkedUrl=https%3A%2F%2Fsamahub3.s3.amazonaws.com%2Fcacheable_client_assets%2Fall%2F23%2Fexternal%2Fprojects%2F13481%2Fuploads%2F226148%2Ftasks%2F62f56dc7881a4c00dffd7a94%2Finputs%2Fvideo%2F000000_New-York-Street.zip",
"name": "task1",
"output_video": [
{
"shapes": [
{
"tags": {},
"type": "rectangle",
"index": 1,
"key_locations": [
{
"points": [
[582, 735],
[674, 735],
[582, 919],
[674, 919]
],
"visibility": 1,
"frame_number": 0
},
{
"points": [
[619, 733],
[711, 733],
[619, 917],
[711, 917]
],
"visibility": 1,
"frame_number": 10
},
{
"points": [
[641, 733],
[733, 733],
[641, 917],
[733, 917]
],
"visibility": 1,
"frame_number": 14
}
]
}
],
"group_type": null,
"frame_count": 15
}
]
}
}
]
Tutorial
Create your JSON and upload a video pre-annotation following this tutorial .
3D Point Cloud
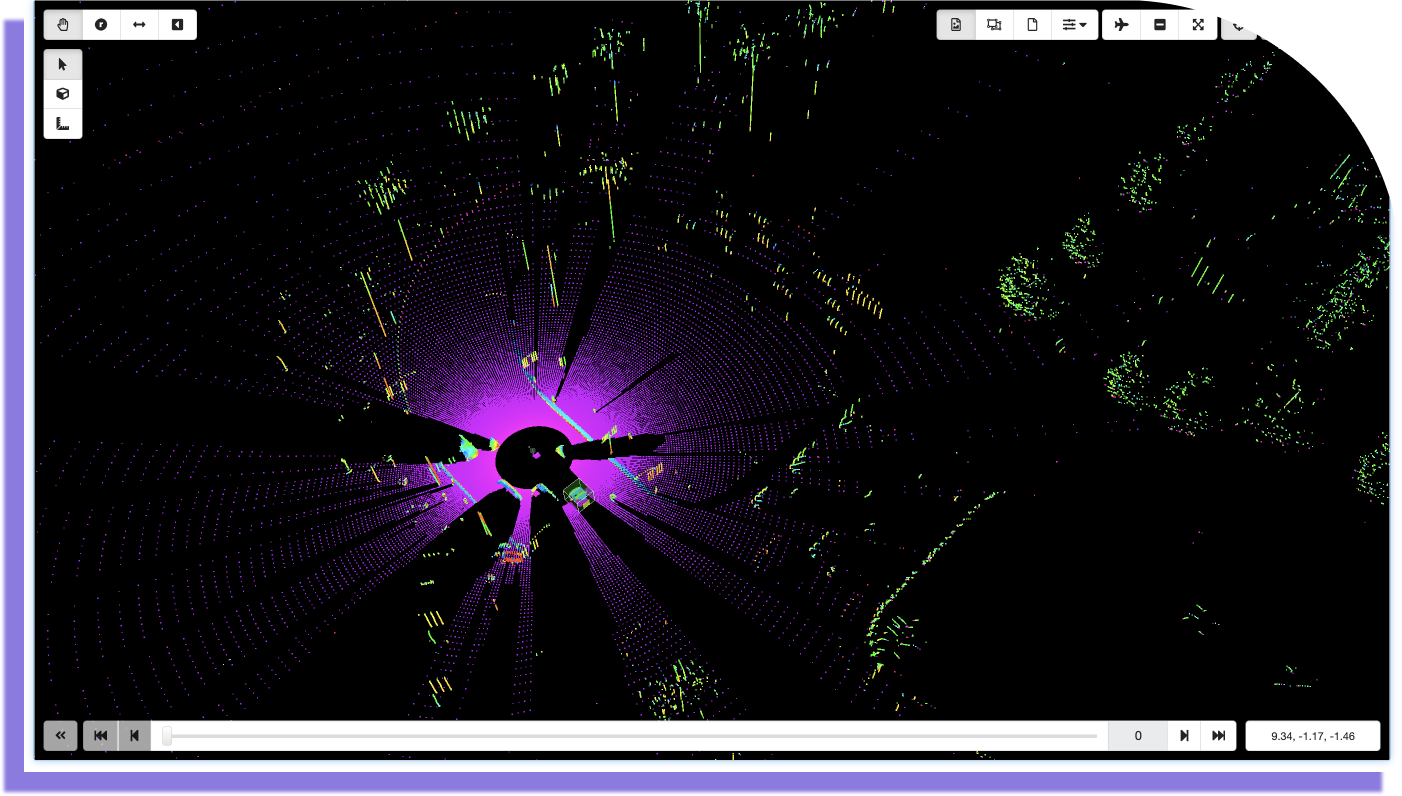
This annotation corresponds to the following output:
3D Point Cloud JSON output
[
{
"priority": 0,
"data": {
"PointCloud Locations": "[[0.0,0.0,0.0,0.711059,0.0,0.0,0.703133],[-0.002738,-0.001571,-0.001672,0.711057,0.001008,0.000153,0.703133],[-0.002372,-0.001363,0.027421,0.711058,0.000855,0.000112,0.703133],[-0.001304,-0.000743,0.049429,0.711059,0.000469,0.000062,0.703133],[-0.000633,-0.000333,0.061071,0.711059,0.000217,0.000033,0.703133],[-0.000282,-0.000131,0.065655,0.711059,0.000091,0.000018,0.703133],[-0.000137,-0.000045,0.06675,0.711059,0.000035,0.000009,0.703133],[-0.000076,-0.000015,0.066582,0.711059,0.000013,0.000005,0.703133],[-0.000076,-0.000015,0.066582,0.711059,0.000013,0.000005,0.703133],[-0.000053,-0.000003,0.066054,0.711059,0.000003,0.000002,0.703133]]",
"PointCloud Translations": "[[0.0,0.0,0.0,0.711059,0.0,0.0,0.703133],[-0.002738,-0.001571,-0.001672,0.711057,0.001008,0.000153,0.703133],[-0.002372,-0.001363,0.027421,0.711058,0.000855,0.000112,0.703133],[-0.001304,-0.000743,0.049429,0.711059,0.000469,0.000062,0.703133],[-0.000633,-0.000333,0.061071,0.711059,0.000217,0.000033,0.703133],[-0.000282,-0.000131,0.065655,0.711059,0.000091,0.000018,0.703133],[-0.000137,-0.000045,0.06675,0.711059,0.000035,0.000009,0.703133],[-0.000076,-0.000015,0.066582,0.711059,0.000013,0.000005,0.703133],[-0.000076,-0.000015,0.066582,0.711059,0.000013,0.000005,0.703133],[-0.000053,-0.000003,0.066054,0.711059,0.000003,0.000002,0.703133]]",
"SensorLoc": "https://sama-client-assets.s3.amazonaws.com/doc-tutorial/3D-Point-Cloud/3D-PC-Fixed-World-Pos.zip",
"Video2SensorCalibration": "https://sama-client-assets.s3.amazonaws.com/doc-tutorial/3D-Point-Cloud/Cam-60-Calib.zip",
"Video1SensorCalibration": "https://sama-client-assets.s3.amazonaws.com/doc-tutorial/3D-Point-Cloud/Cam-0-Calib.zip",
"Video2": "https://assets.samasource.com/api/v1/assets/532f923b-9a40-4981-8f8d-02fa205c3061?linkedUrl=https%3A%2F%2Fsamahub3.s3.amazonaws.com%2Fcacheable_client_assets%2Fall%2F23%2Fexternal%2Fprojects%2F13483%2Fuploads%2F199560%2Ftasks%2F62d1e41d51ffc84ef9150cc7%2Finputs%2FVideo2%2FCam-60.zip",
"Video1": "https://assets.samasource.com/api/v1/assets/7158564e-b759-45a3-a4be-f99b03313ddd?linkedUrl=https%3A%2F%2Fsamahub3.s3.amazonaws.com%2Fcacheable_client_assets%2Fall%2F23%2Fexternal%2Fprojects%2F13483%2Fuploads%2F199560%2Ftasks%2F62d1e41d51ffc84ef9150cc7%2Finputs%2FVideo1%2FCam-0.zip",
"CloudUrl": "https://assets.samasource.com/api/v1/assets/e45803ce-84e8-44fe-ade1-8ed45c99b02f?linkedUrl=https%3A%2F%2Fsamahub3.s3.amazonaws.com%2Fcacheable_client_assets%2Fall%2F23%2Fexternal%2Fprojects%2F13483%2Fuploads%2F199560%2Ftasks%2F62d1e41d51ffc84ef9150cc7%2Finputs%2FCloudUrl%2F3D-PC.zip",
"Name": "task1",
"output_PointCloud": [
{
"shapes": [
{
"tags": {},
"type": "cuboid",
"index": 1,
"key_locations": [
{
"points": [
[-12.4633021048712, -1.603270321472053, -1.74485],
[-12.4633021048712, -1.603270321472053, 0.69225],
[-12.49698836262359, 1.401860880062855, -1.74485],
[-12.49698836262359, 1.401860880062855, 0.69225],
[-9.238114728445836, -1.567117326485837, -1.74485],
[-9.238114728445836, -1.567117326485837, 0.69225],
[-9.271800986198224, 1.43801387504907, -1.74485],
[-9.271800986198224, 1.43801387504907, 0.69225]
],
"visibility": 1,
"frame_number": 0,
"position_center": [-10.86755, -0.08263, -0.5263],
"direction": {
"roll": 0.0,
"pitch": 0.0,
"yaw": -3.130383543353187
},
"dimensions": {
"length": 3.225389999999999,
"width": 3.0053199999999993,
"height": 2.4371
}
}
]
}
],
"group_type": null,
"frame_count": 10
}
]
}
}
]
Important aspect about some nested inputs inside "key_locations"
Even though "position_center", "direction" and "dimensions" come inside "key_locations" when you download the delivery format JSON are not taking on count when uploading pre-annotated tasks.
Tutorial
Create your JSON and upload 3D Point Cloud model predictions following this tutorial .
📘 Note
The Sama Platform also supports model predictions in CSV format. If you are using this format, reach out to your Sama Delivery Manager for more information.